Reading Data with ZQL
ZQL is Zero’s query language.
Inspired by SQL, ZQL is expressed in TypeScript with heavy use of the builder pattern. If you have used Drizzle or Kysely, ZQL will feel familiar.
ZQL queries are composed of one or more clauses that are chained together into a query.
Unlike queries in classic databases, the result of a ZQL query is a view that updates automatically and efficiently as the underlying data changes. You can call a query’s materialize() method to get a view, but more typically you run queries via some framework-specific bindings. For example see useQuery for React or SolidJS.
Select
ZQL queries start by selecting a table. There is no way to select a subset of columns; ZQL queries always return the entire row (modulo column permissions).
const z = new Zero(...);
// Returns a query that selects all rows and columns from the issue table.
z.query.issue;
This is a design tradeoff that allows Zero to better reuse the row locally for future queries. This also makes it easier to share types between different parts of the code.
Ordering
You can sort query results by adding an orderBy clause:
z.query.issue.orderBy('created', 'desc');
Multiple orderBy clauses can be present, in which case the data is sorted by those clauses in order:
// Order by priority descending. For any rows with same priority,
// then order by created desc.
z.query.issue.orderBy('priority', 'desc').orderBy('created', 'desc');
All queries in ZQL have a default final order of their primary key. Assuming the issue table has a primary key on the id column, then:
// Actually means: z.query.issue.orderBy('id', 'asc');
z.query.issue;
// Actually means: z.query.issue.orderBy('priority', 'desc').orderBy('id', 'asc');
z.query.issue.orderBy('priority', 'desc');
Limit
You can limit the number of rows to return with limit():
z.query.issue.orderBy('created', 'desc').limit(100);
Paging
You can start the results at or after a particular row with start():
let start: IssueRow | undefined;
while (true) {
let q = z.query.issue.orderBy('created', 'desc').limit(100);
if (start) {
q = q.start(start);
}
const batch = await q.run();
console.log('got batch', batch);
if (batch.length < 100) {
break;
}
start = batch[batch.length - 1];
}
By default start() is exclusive - it returns rows starting after the supplied reference row. This is what you usually want for paging. If you want inclusive results, you can do:
z.query.issue.start(row, {inclusive: true});
Getting a Single Result
If you want exactly zero or one results, use the one() clause. This causes ZQL to return Row|undefined rather than Row[].
const result = await z.query.issue.where('id', 42).one().run();
if (!result) {
console.error('not found');
}
one() overrides any limit() clause that is also present.
Relationships
You can query related rows using relationships that are defined in your Zero schema.
// Get all issues and their related comments
z.query.issue.related('comments');
Relationships are returned as hierarchical data. In the above example, each row will have a comments field which is itself an array of the corresponding comments row.
You can fetch multiple relationships in a single query:
z.query.issue.related('comments').related('reactions').related('assignees');
Refining Relationships
By default all matching relationship rows are returned, but this can be refined. The related method accepts an optional second function which is itself a query.
z.query.issue.related(
'comments',
// It is common to use the 'q' shorthand variable for this parameter,
// but it is a _comment_ query in particular here, exactly as if you
// had done z.query.comment.
q => q.orderBy('modified', 'desc').limit(100).start(lastSeenComment),
);
This relationship query can have all the same clauses that top-level queries can have.
Nested Relationships
You can nest relationships arbitrarily:
// Get all issues, first 100 comments for each (ordered by modified,desc),
// and for each comment all of its reactions.
z.query.issue.related('comments', q =>
q.orderBy('modified', 'desc').limit(100).related('reactions'),
);
Where
You can filter a query with where():
z.query.issue.where('priority', '=', 'high');
The first parameter is always a column name from the table being queried. Intellisense will offer available options (sourced from your Zero Schema).
Comparison Operators
Where supports the following comparison operators:
| Operator | Allowed Operand Types | Description |
|---|---|---|
= , != | boolean, number, string | JS strict equal (===) semantics |
< , <=, >, >= | number | JS number compare semantics |
LIKE, NOT LIKE, ILIKE, NOT ILIKE | string | SQL-compatible LIKE / ILIKE |
IN , NOT IN | boolean, number, string | RHS must be array. Returns true if rhs contains lhs by JS strict equals. |
IS , IS NOT | boolean, number, string, null | Same as = but also works for null |
TypeScript will restrict you from using operators with types that don’t make sense – you can’t use > with boolean for example.
Equals is the Default Comparison Operator
Because comparing by = is so common, you can leave it out and where defaults to =.
z.query.issue.where('priority', 'high');
Comparing to null
As in SQL, ZQL’s null is not equal to itself (null ≠ null).
This is required to make join semantics work: if you’re joining employee.orgID on org.id you do not want an employee in no organization to match an org that hasn’t yet been assigned an ID.
When you purposely want to compare to null ZQL supports IS and IS NOT operators that work just like in SQL:
// Find employees not in any org.
z.query.employee.where('orgID', 'IS', null);
TypeScript will prevent you from comparing to null with other operators.
Compound Filters
The argument to where can also be a callback that returns a complex expression:
// Get all issues that have priority 'critical' or else have both
// priority 'medium' and not more than 100 votes.
z.query.issue.where(({cmp, and, or, not}) =>
or(
cmp('priority', 'critical'),
and(cmp('priority', 'medium'), not(cmp('numVotes', '>', 100))),
),
);
cmp is short for compare and works the same as where at the top-level except that it can’t be chained and it only accepts comparison operators (no relationship filters – see below).
Note that chaining where() is also a one-level and:
// Find issues with priority 3 or higher, owned by aa
z.query.issue.where('priority', '>=', 3).where('owner', 'aa');
Comparing Literal Values
The where clause always expects its first parameter to be a column name as a string. Same with the cmp helper:
// "foo" is a column name, not a string:
z.query.issue.where('foo', 'bar');
// "foo" is a column name, not a string:
z.query.issue.where(({cmp}) => cmp('foo', 'bar'));
To compareto a literal value, use the cmpLit helper:
z.query.issue.where(cmpLit('foobar', 'foo' + 'bar'));
By itself this is not very useful, but the first parameter can also be a JavaScript variable:
z.query.issue.where(cmpLit(role, 'admin'));
Or, within a permission rule, you can compare to a field of the authData parameter:
z.query.issue.where(cmpLit(authData.role, 'admin'));
Relationship Filters
Your filter can also test properties of relationships. Currently the only supported test is existence:
// Find all orgs that have at least one employee
z.query.organization.whereExists('employees');
The argument to whereExists is a relationship, so just like other relationships it can be refined with a query:
// Find all orgs that have at least one cool employee
z.query.organization.whereExists('employees', q =>
q.where('location', 'Hawaii'),
);
As with querying relationships, relationship filters can be arbitrarily nested:
// Get all issues that have comments that have reactions
z.query.issue.whereExists('comments',
q => q.whereExists('reactions'));
);
The exists helper is also provided which can be used with and, or, cmp, and not to build compound filters that check relationship existence:
// Find issues that have at least one comment or are high priority
z.query.issue.where({cmp, or, exists} =>
or(
cmp('priority', 'high'),
exists('comments'),
),
);
Completeness
Zero returns whatever data it has on the client immediately for a query, then falls back to the server for any missing data. Sometimes it's useful to know the difference between these two types of results. To do so, use the result from useQuery:
const [issues, issuesResult] = useQuery(z.query.issue);
if (issuesResult.type === 'complete') {
console.log('All data is present');
} else {
console.log('Some data is missing');
}
The possible values of result.type are currently complete and unknown.
The complete value is currently only returned when Zero has received the server result. But in the future, Zero will be able to return this result type when it knows that all possible data for this query is already available locally. Additionally, we plan to add a prefix result for when the data is known to be a prefix of the complete result. See Consistency for more information.
Handling Missing Data
It is inevitable that there will be cases where the requested data cannot be found. Because Zero returns local results immediately, and server results asynchronously, displaying "not found" / 404 UI can be slightly tricky. If you just use a simple existence check, you will often see the 404 UI flicker while the server result loads:
const [issue, issuesResult] = useQuery(
z.query.issue.where('id', 'some-id').one(),
);
// ❌ This causes flickering of the UI
if (!issue) {
return <div>404 Not Found</div>;
} else {
return <div>{issue}</div>;
}
The way to do this correctly is to only display the "not found" UI when the result type is complete. This way the 404 page is slow but pages with data are still just as fast.
const [issue, issuesResult] = useQuery(
z.query.issue.where('id', 'some-id').one(),
);
if (!issue && issueResult.type === 'complete') {
return <div>404 Not Found</div>;
}
if (!issue) {
return null;
}
return <div>{issue}</div>;
Listening to Changes
Currently, the way to listen for changes in query results is not ideal. You can add a listener to a materialized view which has the new data and result as parameters:
z.query.issue.materialize().addListener((issues, issuesResult) => {
// do stuff...
});
However, using this method will maintain its own materialized view in memory which is wasteful. It also doesn't allow for granular listening to events like add and remove of rows.
A better way would be to create your own view without actually storing the data which will also allow you to listen to specific events. Again, the API is not good and will be improved in the future.
// Inside the View class
// Instead of storing the change, we invoke some callback
push(change: Change): void {
switch (change.type) {
case 'add':
this.#onAdd?.(change)
break
case 'remove':
this.#onRemove?.(change)
break
case 'edit':
this.#onEdit?.(change)
break
case 'child':
this.#onChild?.(change)
break
default:
throw new Error(`Unknown change type: ${change['type']}`)
}
}
(see View implementations in zero-vue or zero-solid)
Preloading
Almost all Zero apps will want to preload some data in order to maximize the feel of instantaneous UI transitions.
In Zero, preloading is done via queries – the same queries you use in the UI and for auth.
However, because preload queries are usually much larger than a screenful of UI, Zero provides a special preload() helper to avoid the overhead of materializing the result into JS objects:
// Preload the first 1k issues + their creator, assignee, labels, and
// the view state for the active user.
//
// There's no need to render this data, so we don't use `useQuery()`:
// this avoids the overhead of pulling all this data into JS objects.
z.query.issue
.related('creator')
.related('assignee')
.related('labels')
.related('viewState', q => q.where('userID', z.userID).one())
.orderBy('created', 'desc')
.limit(1000)
.preload();
Data Lifetime and Reuse
Zero reuses data synced from prior queries to answer new queries when possible. This is what enables instant UI transitions.
But what controls the lifetime of this client-side data? How can you know whether any particular query will return instant results? How can you know whether those results will be up to date or stale?
The answer is that the data on the client is simply the union of rows returned from queries which are currently syncing. Once a row is no longer returned by any syncing query, it is removed from the client. Thus, there is never any stale data in Zero.
So when you are thinking about whether a query is going to return results instantly, you should think about what other queries are syncing, not about what data is local. Data exists locally if and only if there is a query syncing that returns that data.
Query Lifecycle
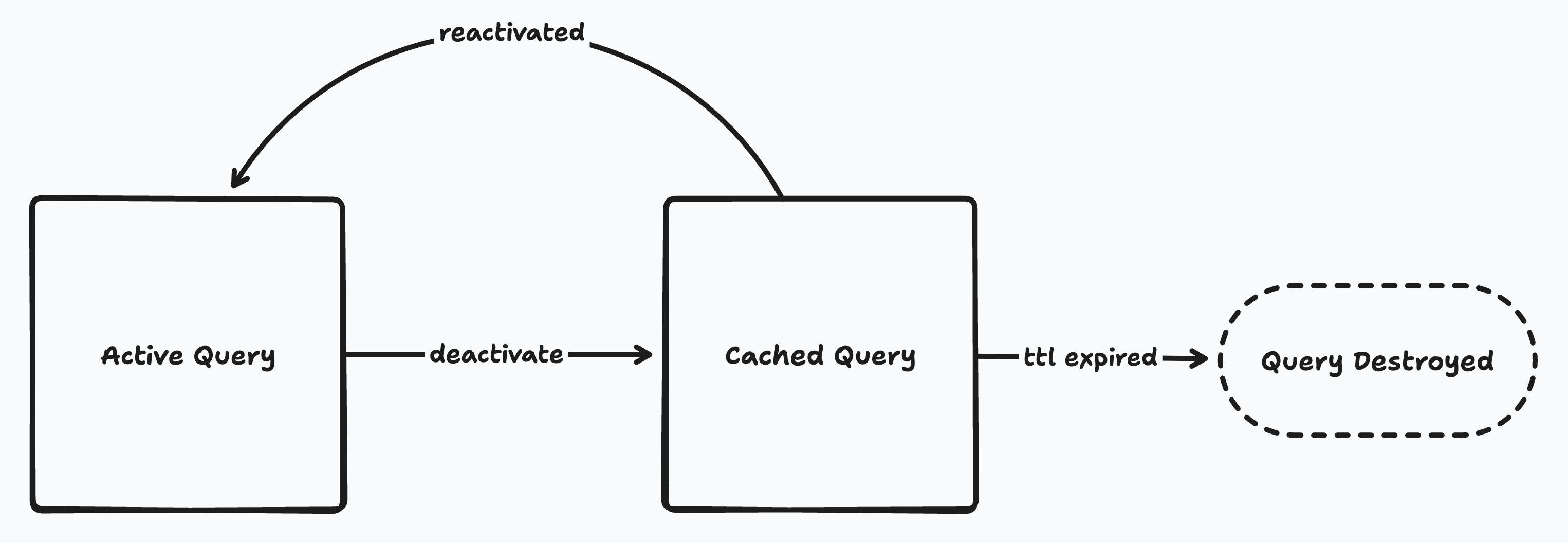
The lifecycle of a ZQL query.
Queries can be either active or cached. An active query is one that is currently being used by the application. Cached queries are not currently in use, but continue syncing in case they are needed again soon.
Active queries are created one of three ways:
- The app calls
q.materialize()to get aView. - The app uses a framework binding like React's
useQuery(q). - The app calls
preload()to sync larger queries without a view.
Active queries sync until they are deactivated. The way this happens depends on how the query was created:
- For
materialize()queries, the UI callsdestroy()on the view. - For
useQuery(), the UI unmounts the component (which callsdestroy()under the covers). - For
preload(), the UI callscleanup()on the return value ofpreload().
Additionally when a Zero instance closes, all active queries are automatically deactivated. This also happens when the containing page or script is unloaded.
TTLs
Each query has a ttl that controls how long it stays cached.
TTL Defaults
In most cases, the default TTL should work well:
preload()queries default tottl:'none', meaning they are not cached at all, and will stop syncing immediately when deactivated. But becausepreload()queries are typically registered at app startup and never shutdown, and because the ttl clock only ticks while Zero is running, this means that preload queries never get unregistered.- Other queries have a default
ttlof5m(five minutes).
Setting Different TTLs
You can override the default TTL with the ttl parameter:
// With useQuery():
const [user] = useQuery(
z.query.user.where('id', userId),
{ttl: '5m'});
// With preload():
z.query.user.where('id', userId).preload(
{ttl: '5m'});
// With materialize():
const view = z.query.user.where('id', userId).materialize(
{ttl: '5m'});
TTLs up to 10m (ten minutes) are currently supported. The following formats are allowed:
| Format | Meaning |
|---|---|
none | No caching. Query will immediately stop when deactivated. |
%ds | Number of seconds. |
%dm | Number of minutes. |
Choosing a TTL
If you choose a different TTL, you should consider how likely it is that the query will be reused, and how far into the future this reuse will occur. Here are some guidelines to help you choose a TTL for common query types:
Preload Queries
These queries load the most commonly needed data for your app. They are typically larger, run with the preload() method, and stay running the entire time your app is running.
Because these queries run the entire time Zero runs, they do not need any TTL to keep them alive. And using a ttl for them is wasteful since when your app changes its preload query, it will end up running the old preload query and the new preload query, even though the app only cares about the new one.
Recommendation: ttl: 'none' (the default for preload()).
Navigational Queries
These queries load data specific to a route. They are typically smaller and run with the useQuery() method. It is useful to cache them for a short time, so that they can be reactivated quickly if the user navigates back to the route.
Recommendation: ttl: '5m' (the default for useQuery()).
Ephemeral Queries
These queries load data for a specific, short-lived user interaction and often come in large numbers (e.g., typeahead search).
The chance of any specific ephemeral query being reused is low, so the benefit of caching them is also low.
Recommendation: useQuery(..., {ttl: 'none'}))*.
Why Zero TTLs are Short
Zero queries are not free.
Just as in any database, queries consume resources on both the client and server. Memory is used to keep metadata about the query, and disk storage is used to keep the query's current state.
We do drop this state after we haven't heard from a client for awhile, but this is only a partial improvement. If the client returns, we have to re-run the query to get the latest data.
This means that we do not actually want to keep queries active unless there is a good chance they will be needed again soon.
The default Zero TTL values might initially seem too short, but they are designed to work well with the way Zero's TTL clock works and strike a good balance between keeping queries alive long enough to be useful, while not keeping them alive so long that they consume resources unnecessarily.
Running Queries Once
Usually subscribing to a query is what you want in a reactive UI, but every so often you'll need to run a query just once. To do this, use the run() method:
const results = await z.query.issue.where('foo', 'bar').run();
By default, run() only returns results that are currently available on the client. That is, it returns the data that would be given for result.type === 'unknown'.
If you want to wait for the server to return results, pass {type: 'complete'} to run:
const results = await z.query.issue.where('foo', 'bar').run({type: 'complete'});
Consistency
Zero always syncs a consistent partial replica of the backend database to the client. This avoids many common consistency issues that come up in classic web applications. But there are still some consistency issues to be aware of when using Zero.
For example, imagine that you have a bug database w/ 10k issues. You preload the first 1k issues sorted by created.
The user then does a query of issues assigned to themselves, sorted by created. Among the 1k issues that were preloaded imagine 100 are found that match the query. Since the data we preloaded is in the same order as this query, we are guaranteed that any local results found will be a prefix of the server results.
The UX that result is nice: the user will see initial results to the query instantly. If more results are found server-side, those results are guaranteed to sort below the local results. There's no shuffling of results when the server response comes in.
Now imagine that the user switches the sort to ‘sort by modified’. This new query will run locally, and will again find some local matches. But it is now unlikely that the local results found are a prefix of the server results. When the server result comes in, the user will probably see the results shuffle around.
To avoid this annoying effect, what you should do in this example is also preload the first 1k issues sorted by modified desc. In general for any query shape you intend to do, you should preload the first n results for that query shape with no filters, in each sort you intend to use.
In the future, we will be implementing a consistency model that fixes these issues automatically. We will prevent Zero from returning local data when that data is not known to be a prefix of the server result. Once the consistency model is implemented, preloading can be thought of as purely a performance thing, and not required to avoid unsightly flickering.